
You don’t need to be a scripting expert.
Our UI guides you through creating complex pipelines without crashing your system.
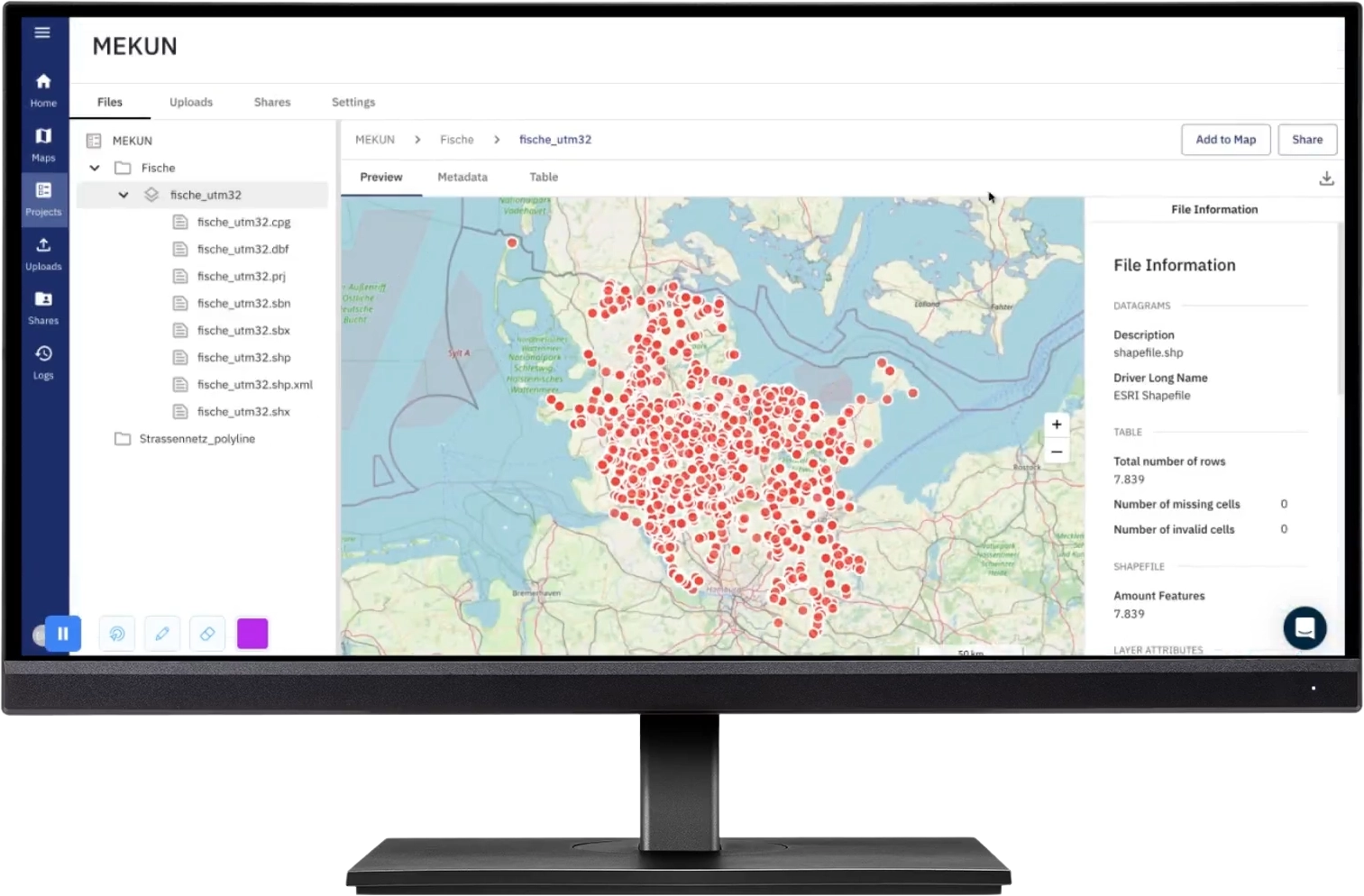
Watch how easily you can set up an entire ocean big data processing workflow.
Upload your files, select the activity, and let the engine do the rest.









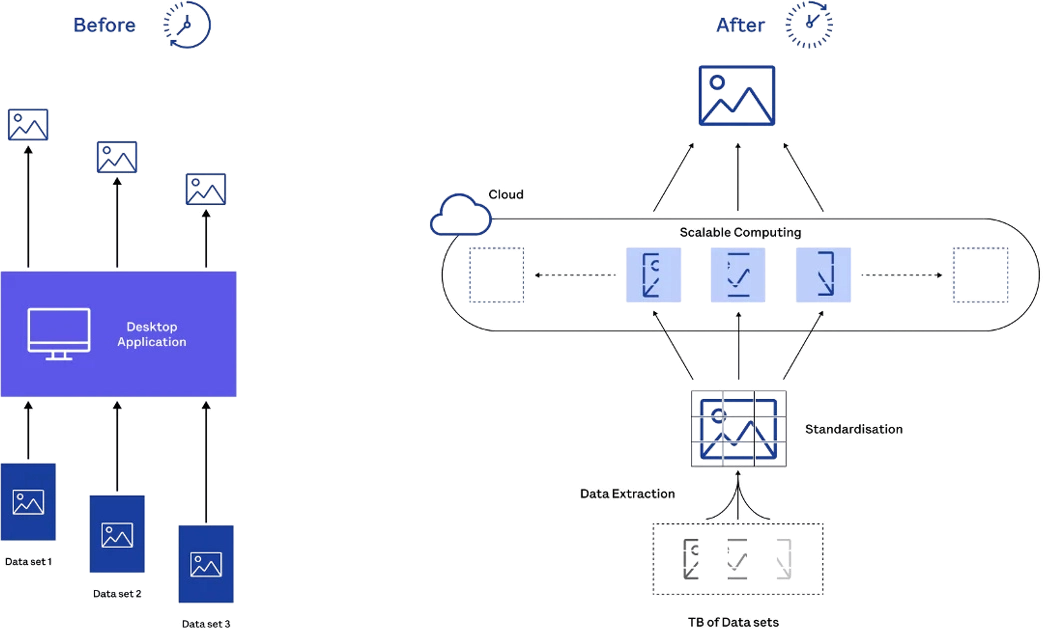

Stop wasting time with crashing software and manual processing.
Let's discover how to accelerate ocean data processing and generating insights in seconds.
Experience the future of ocean data processing.






